Abstract
The evaluation of long-term video quality understanding remains an open challenge for large
vision–language models (LVLMs). Existing video quality benchmarks predominantly focus on short
clips and isolated distortions, overlooking the temporal continuity, cumulative degradation, and
reasoning complexity inherent in long-duration content. To address these limitations, we present
LongVQUBench, a comprehensive benchmark for
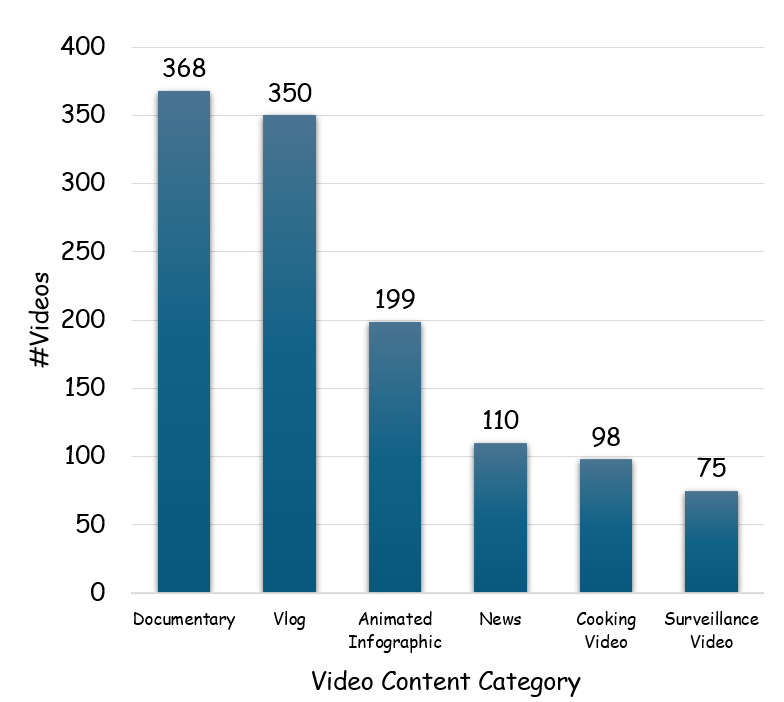
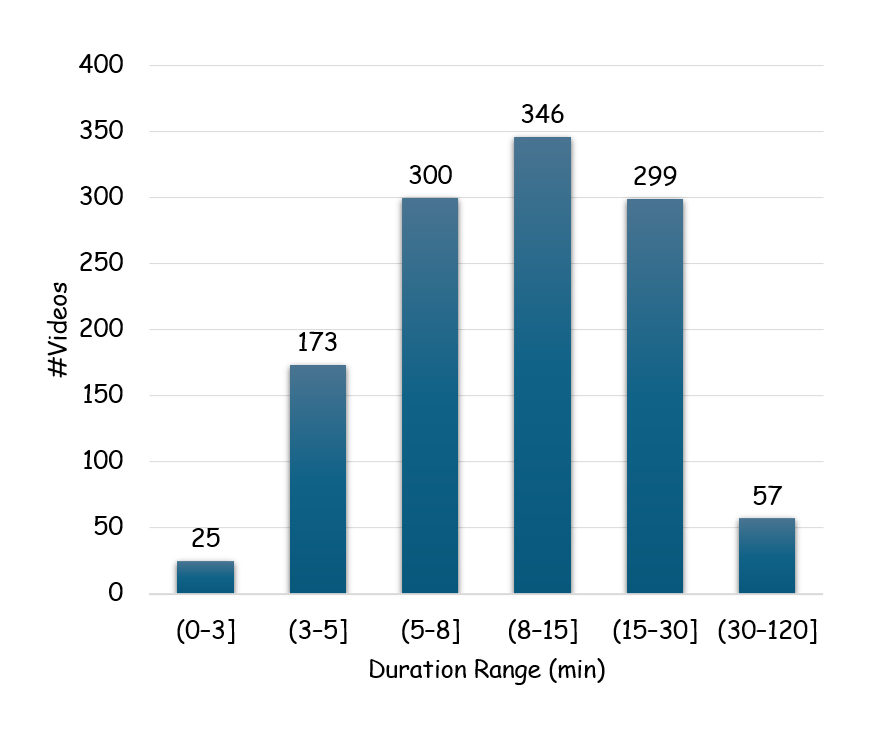
long-term video quality understanding. LongVQUBench contains over 1,200 diverse videos spanning
movies, documentaries, surveillance footage, egocentric recordings, and animated content,
accompanied by 1,500 multiple-choice and open-ended questions for validation and testing.
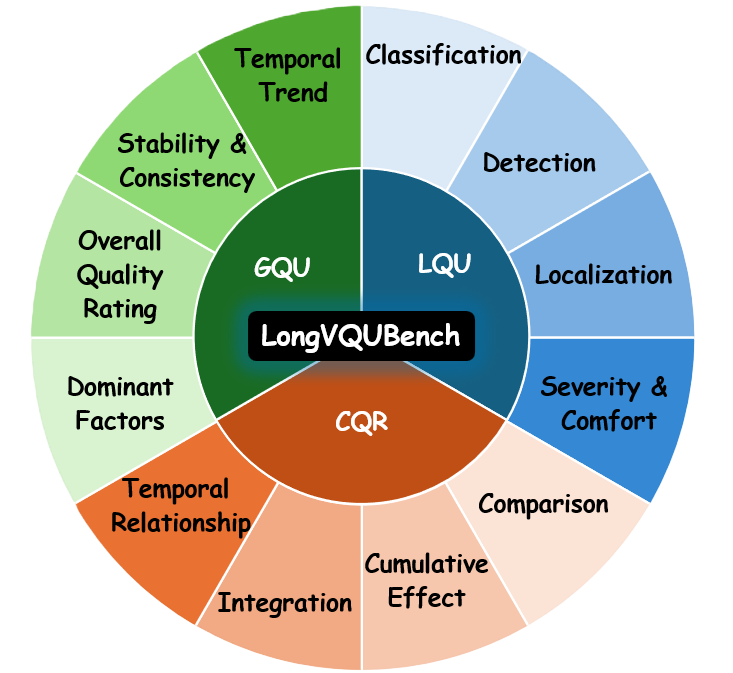
To assess perceptual reasoning across different temporal scopes, we introduce three progressively
complex evaluation levels: (i) local event quality understanding (LQU) for
analyzing localized distortions; (ii) cross-event quality reasoning (CQR) for
integrating multiple degraded events; and (iii) global quality understanding
(GQU) for holistic perceptual evaluation over extended durations. Furthermore, a
needle distortion question-answering (NDQA) paradigm is embedded across all
three levels, where subtle spatial or temporal artifacts are sparsely inserted to probe
fine-grained detection and reasoning capabilities. Extensive experiments on 14 state-of-the-art
LVLMs reveal significant performance degradation with increasing video length and reasoning depth,
highlighting their limited capacity for long-range temporal integration and perceptual attribution.
Long-term Video Quality Understanding
Video Quality Benchmark
Large Vision–Language Models
 LongVQUBench
LongVQUBench